
Heading
TaxCalcBench: a first-ever benchmark for evaluating AI’s ability to calculate tax returns


TL;DR
AI can’t do your taxes on its own (yet).
- Column Tax is on a mission to apply AI to the tax domain to make it so every American can confidently file taxes in one-click. In our new research paper and associated code & data repository we present a new benchmark, TaxCalcBench, for evaluating frontier AI models’ performance and reliability in calculating realistic tax returns.
- This is a first-of-its-kind benchmark. Because of the limited availability of personal income tax calculation engines in the US, the dataset behind this benchmark is very hard to come by. The dataset includes 51 realistic pairs of inputs representing taxpayer data (e.g. W-2s) and the corresponding correctly-computed Form 1040 in IRS XML format.
- Results show that AI models consistently struggle with critical tax tasks, frequently misusing IRS tax tables and making calculation errors, underscoring that current LLMs alone are insufficient for reliably computing personal tax returns without additional scaffolding & orchestration.
Background: what is tax calculation?
Tax filing consists of 3 main subtasks:
- Document collection: collecting all of the documents (e.g. W-2s) required for filing.
- Preparation: entering all of the collected information into tax preparation software.
- Calculation: transforming the entered information into the completed tax return (Form 1040, for personal income tax) for filing.
TaxCalcBench is solely focused on (3) Calculation.
To date, companies have built "tax calculation engines" as deterministic software: code that can compute the tax return given a user's information.
Tax filing is an exercise in once-a-year personal financial data collection: you collect all of your financial data & facts for the year (e.g. W-2s, 1099s, your dependents' DoBs, your spouse's data if you're married), so that you or your accountant can enter it into tax software. Tax software developers call these your “inputs”.
A tax engine takes those “inputs” and runs them through calculations and transformations defined by the IRS, state, and local agencies. A tax engine then outputs the completed tax return in the XML format specified by the IRS to be e-filed and a PDF for users to view their return.
Those calculations & transformations are only defined in English. The core challenge of building a traditional tax engine is turning those English calculations into programmatic code that can compute a user’s tax return, 100% accurately, for every possible permutation of user inputs.
One example is Line 1a of Form 1040: "Total amount from Form(s) W-2, box 1 (see instructions)". If the user has two W-2s, one with $30k in box 1 and the other with $20k in box 1, Form 1040 Line 1a will be the sum, $50k:

The code behind the scenes of that calculation might look something like:
line_1a = sum(w2.box_1 for w2 in w2s) - sum(sch_c.temporary_statutory_employee for sch_c
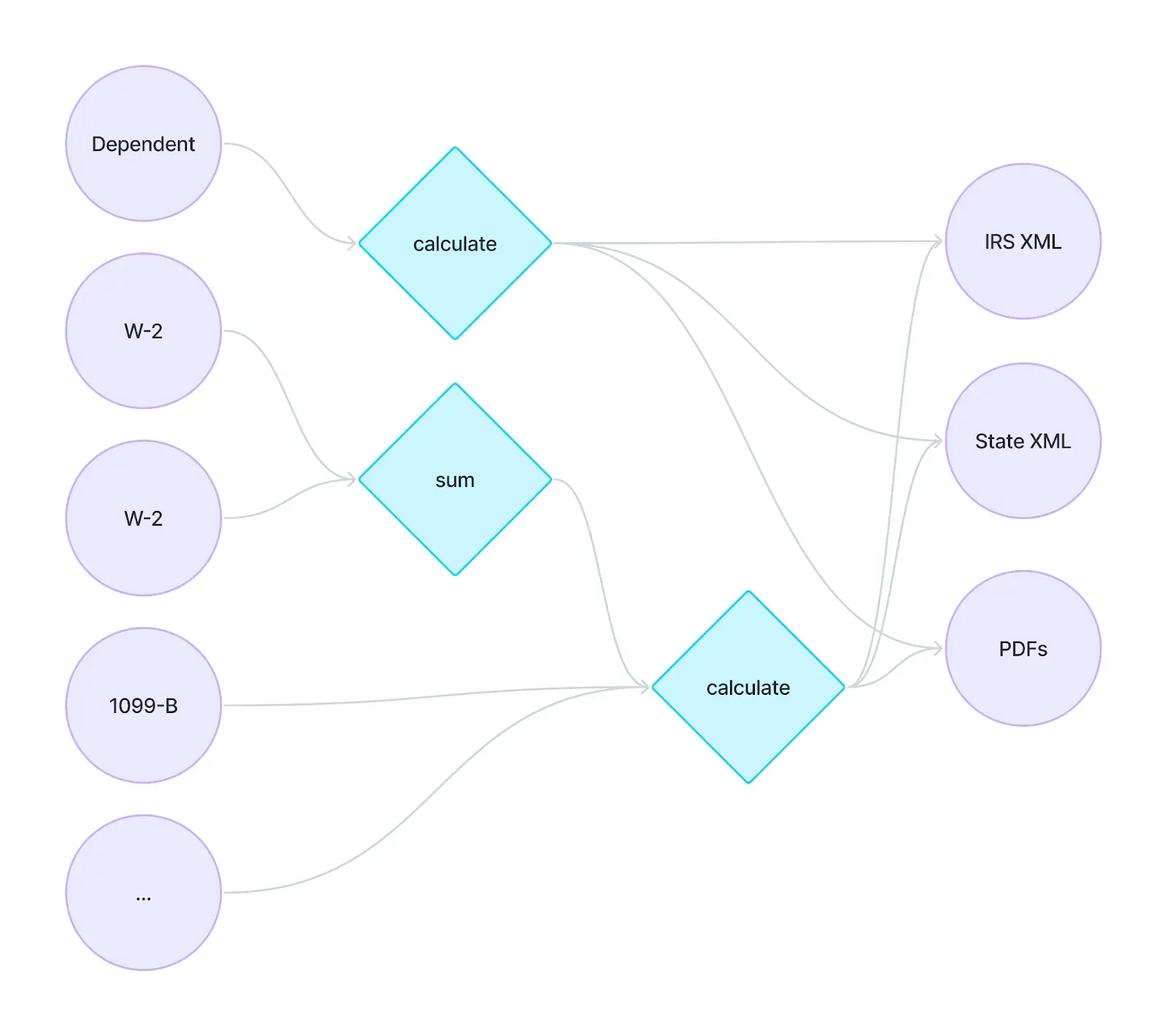
in schedules_c) - schedule_1.nonqualified_deferred_compensationFor a sense of scale, the US income tax code, across Federal & ~40 states, is more than 75k pages and over a million lines of text total. It's not the arithmetic operations (mostly addition, subtraction, multiplication, division) themselves that are particularly difficult. Instead, it’s the number of rules and the number of interconnections between those rules – in addition to the fact that there is no given “answer key” from the IRS or States – that makes this problem hard. A single input like Filing Status is a dependency with downstream impacts on thousands of additional calculations on the Form 1040 alone.
Traditional tax engines1 have built this computation graph by-hand (or in Column Tax’s case, via our Tax development agent, Iris). In this simplified diagram, each node like "calculate" and "sum" represents a single calculation like the Line 1a example above. These calculations are very interconnected and eventually produce the expected output (in XML & PDF formats):
TaxCalcBench
The TaxCalcBench eval is a dataset of 51 pairs of user inputs and the expected correctly-computed tax return output as well as a testing harness that compares models’ output to the expected result.
The TaxCalcBench dataset
The dataset represents a mix of tax situations (income types, filing statuses, credits & deductions) for a fairly simple set of Federal-only tax returns (e.g. for users who live in non-income tax states like Florida & Texas).
This dataset is hard to come by: it's been crafted by hand by Column Tax’s expert team of human Tax Software Analysts.
The inputs represent all of the information needed to fully calculate the output return. A portion of the input representing a user's W-2s (shortened for clarity) looks like:
"w2": [
{
"employer_name": {
"label": "Employer’s name",
"value": "Acme Corp"
},
"wages": {
"label": "Box 1",
"value": 50000
},
"withholding": {
"label": "Box 2",
"value": 2000
},
"social_security_wages": {
"label": "Box 3",
"value": 50000
},
"social_security_tax": {
"label": "Box 4",
"value": 3100
},
"medicare_wages_and_tips": {
"label": "Box 5",
"value": 50000
},
"medicare_tax_withheld": {
"label": "Box 6",
"value": 725
}
}
]
The outputs are formatted as IRS-expected "Modernized e-File (MeF)" XML.
A portion of the output (shortened for clarity) looks like:
<IRS1040 documentId="1">
<IndividualReturnFilingStatusCd>1</IndividualReturnFilingStatusCd>
<VirtualCurAcquiredDurTYInd>false</VirtualCurAcquiredDurTYInd>
<TotalExemptPrimaryAndSpouseCnt>1</TotalExemptPrimaryAndSpouseCnt>
<TotalExemptionsCnt>1</TotalExemptionsCnt>
<WagesAmt referenceDocumentId="IRSW2-0">50000</WagesAmt>
<WagesSalariesAndTipsAmt>50000</WagesSalariesAndTipsAmt>
<TotalIncomeAmt>50000</TotalIncomeAmt>
<AdjustedGrossIncomeAmt>50000</AdjustedGrossIncomeAmt>
<TotalItemizedOrStandardDedAmt>14600</TotalItemizedOrStandardDedAmt>
<TotalDeductionsAmt>14600</TotalDeductionsAmt>
</IRS1040>
This dataset consists of only Tax Year 2024 (TY24) returns. The dataset contains federal-only returns for fairly simple tax situations and includes features like:
- Filing statuses: Single, Married Filing Jointly, and Head of Household
- Income sources: W-2, self-employed, capital gains, interest, and dividends
- Credits & deductions: Child Tax Credit, Earned Income Tax Credit, Child and Dependent Care Expenses
Benchmark construction
We constructed TaxCalcBench by utilizing a subset of the tests we use to test our tax calculation engine. These tests were created by human experts and are verified by a deterministic tax engine.
While these test cases represent tax return situations of many Americans, the actual data in these tests is totally synthetic: no real taxpayer data is represented in this test data at all.
Experiment Methodology
TaxCalcBench tests models with a knowledge cutoff in 2025 on their ability to natively calculate a correct tax return for the 2024 Tax Year: Gemini 2.5 Pro, Gemini 2.5 Flash, Claude Opus 4, and Claude Sonnet 4
The baseline for performance is 100% because the models are being compared to a deterministic “traditional code” engine.
TaxCalcBench conducts its tests by prompting the model to calculate a tax return given the full set of user inputs. Here is the prompt used, which asks the model to output the return in a simplified text-only format (not the proper XML because models can't yet natively produce MeF schema-compatible XML2):
Form [NUMBER]: [NAME]
==================
Line 1: [Description] | [Explanation of calculations, if any] | [Amount]
Line 2: [Description] | [Explanation of calculations, if any] | [Amount]
...
Each run is evaluated by:
- Correct returns (strict): Model outputted returns are considered correct if the amounts strictly match for every evaluated line. This is the only actual metric that matters in the end because the IRS expects 100%-correctly computed tax returns3.
- TaxCalcBench also evaluates and reports on these additional metrics that give additional color to the models' performances:
- Correct returns (lenient): if every evaluated line is within +/- $5 of the expected value.
- Correct (by line): the percent of evaluated lines that match the expected value.
- Correct (by line, lenient): the percent of evaluated lines that are within +/- $5 of the expected value.
Key findings
Models can't calculate tax returns reliably today.
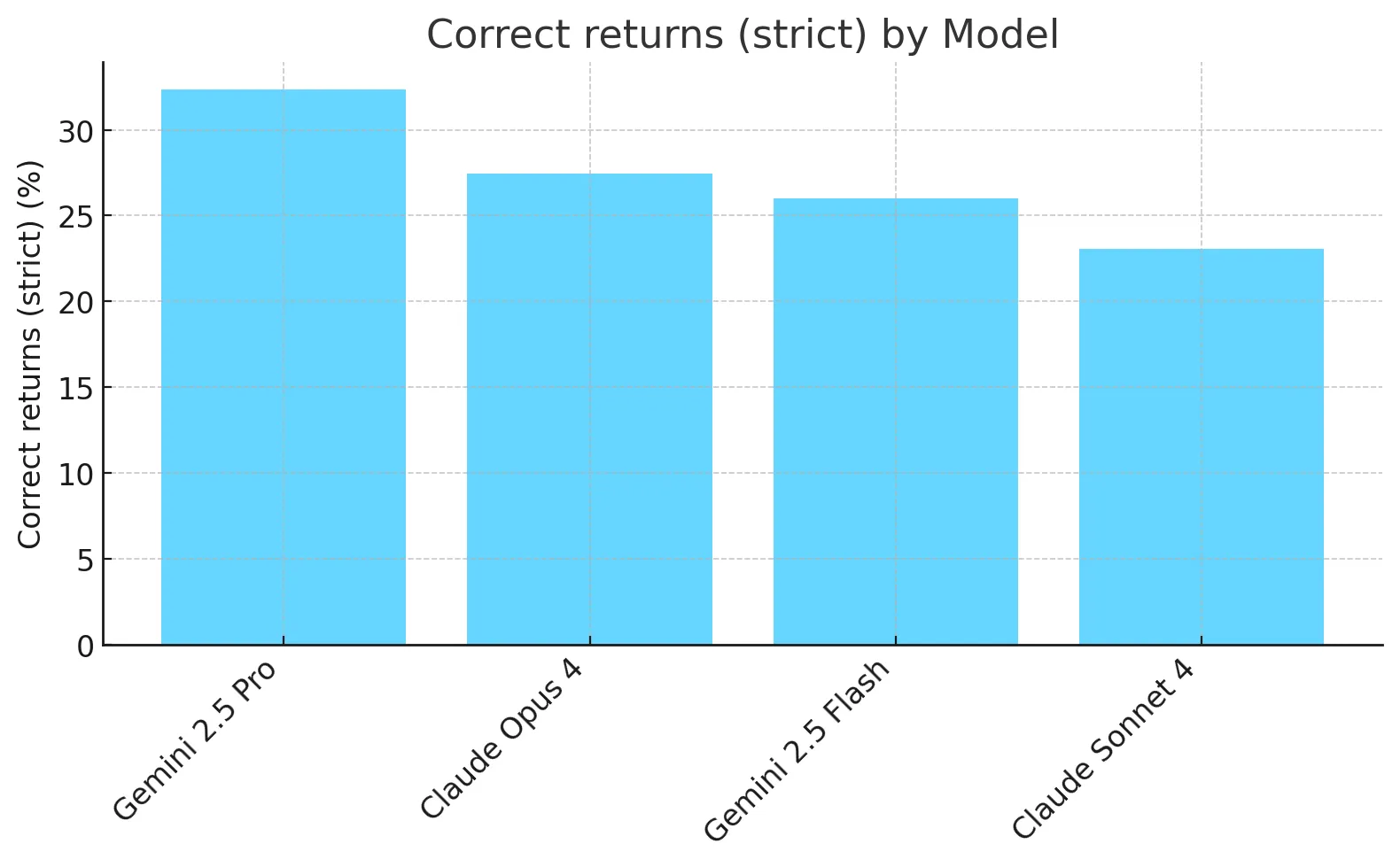
- Even the best-performing model (Gemini 2.5 Pro) scores only in the mid-30% range for Correct returns.
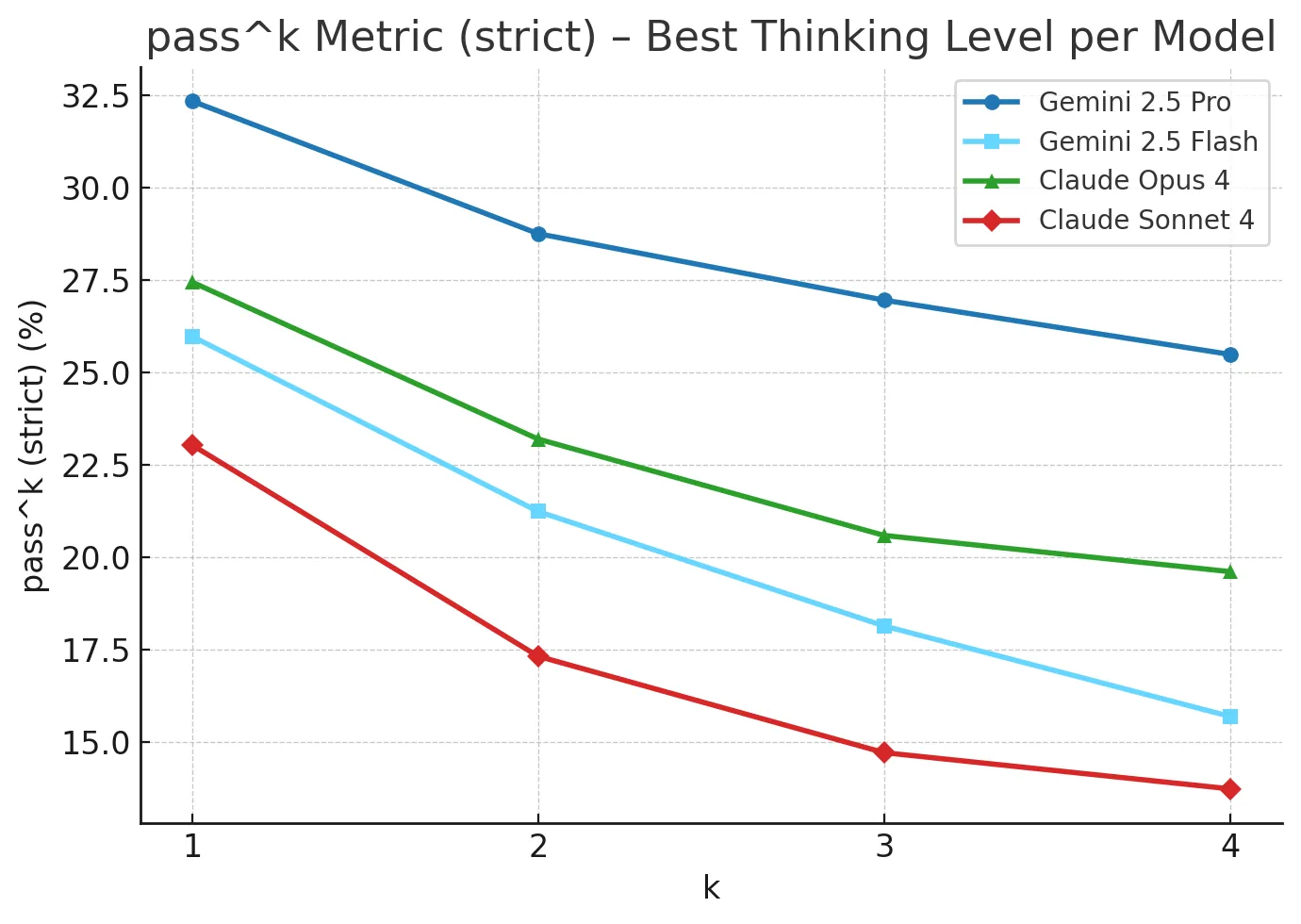
- Models are inconsistent in their calculations - This is not acceptable for a task which needs consistently correct results with clear auditability. Scores reliably decrease as we increase k in the pass^k metric.
- While frontier models can calculate some of the simplest returns, they reliably fail to calculate some parts of tax law, e.g. the Child Tax Credit or Earned Income Tax Credit which include complex eligibility requirements.
There are some bright spots:
- Models do better on the lenient metric: for many returns, the models are only a few dollars off on some lines. This is mostly due to the tax calculation, which in reality relies on a large lookup table (discussed in more detail in the Results Analysis below), but models are often using bracket-based percentage calculations instead, leading to small discrepancies.
- Models are better than their overall correct return results on a per line basis: this indicates that there are often single mistakes (discussed in more detail in the Results Analysis below) on the tax return that cascade throughout the rest of the lines, leading to incorrect returns overall.
The prompt matters. As part of this experiment, we experimented with prompting to find a prompt we thought to be fair for evaluating models' performance. We landed on a prompt with the following features:
- Instructions that the model is helping test tax calculation software: this is because at the time of testing, model safeguards by-default would sometimes refuse to prepare/calculate what it believed to be a real tax return
- Instructions to calculate the main Form 1040 and any necessary forms/schedules
- Ability to skip the SSN field for "privacy" (again, to ensure the model did not refuse for privacy/security safeguards)
- A full explanation of the desired output format including line-by-line instructions for the Form 1040
- An explanation of the data input format
Result analysis
Models fail to correctly compute tax returns in two main ways:
- Using tax bracket percentage-based calculations instead of proper lookup tables (15-20% of test cases)
- Calculation errors
Using tax bracket percentage-based calculations
The 15-20% delta between strictly Correct returns and Correct returns scored on the lenient metric (+/- $5 difference allowed per-line) is often based on models using percentage, bracket-based calculations for Line 16 of the Form 1040 tax return. This is the line that computes your total tax liability for the year.
Percentage, bracket-based calculations are the commonly-thought-of method for computing tax liability: e.g. M% of your first $Nk of income + and O% of your next $Pk of income. But in reality, the IRS instructions for Form 1040 clearly state “If your taxable income is less than $100,000, you must use the Tax Table, later in these instructions, to figure your tax. Be sure you use the correct column. If your taxable income is $100,000 or more, use the Tax Computation Worksheet right after the Tax Table.”
Line 15: Subtract line 14 from line 11. If zero or less, enter -0-. This is your taxable income | $47,900 - $21,900 | 26000
Line 16: Tax | Tax on $26,000 for HOH: $16,550 × 10% + $9,450 × 12% | 2789which is graded as incorrect by the evaluator as compared to the proper XML because it’s off by $3:
Line 16: ✗ incorrect, expected: 2792.0, actual: 2789.0In reality, the IRS is expecting the use of the Tax look up Table, finding the exact Tax amount for taxpayers with a Head of Household filing status (as in this example) with between $26,000 and $26,050 in taxable income:


We can think of methods that could augment the models in order to force them to use the proper Tax Tables to improve on this common error case.
Calculation errors
The majority of return completions attempted by the models have some sort of calculation error. Here is one prototypical example:
In one example run, the model hallucinates incorrect line numbers on Form 8962:
Form 8962: Premium Tax Credit (PTC)
===================================
Line 1: Annual household income | Your adjusted gross income | 28,125
Line 2: Household size | Total number of individuals in your tax household | 1
Line 3: Household income as a percentage of federal poverty line (FPL) | Line 1 / FPL for your household size ($15,060) | 186.75%Lines 1 and 2 are incorrectly swapped, and Line 3 should be “Household income. Add the amounts on lines 2a and 2b. See instructions” not “Household income as a percentage of federal poverty line”.
Here is the correct Form for comparison:
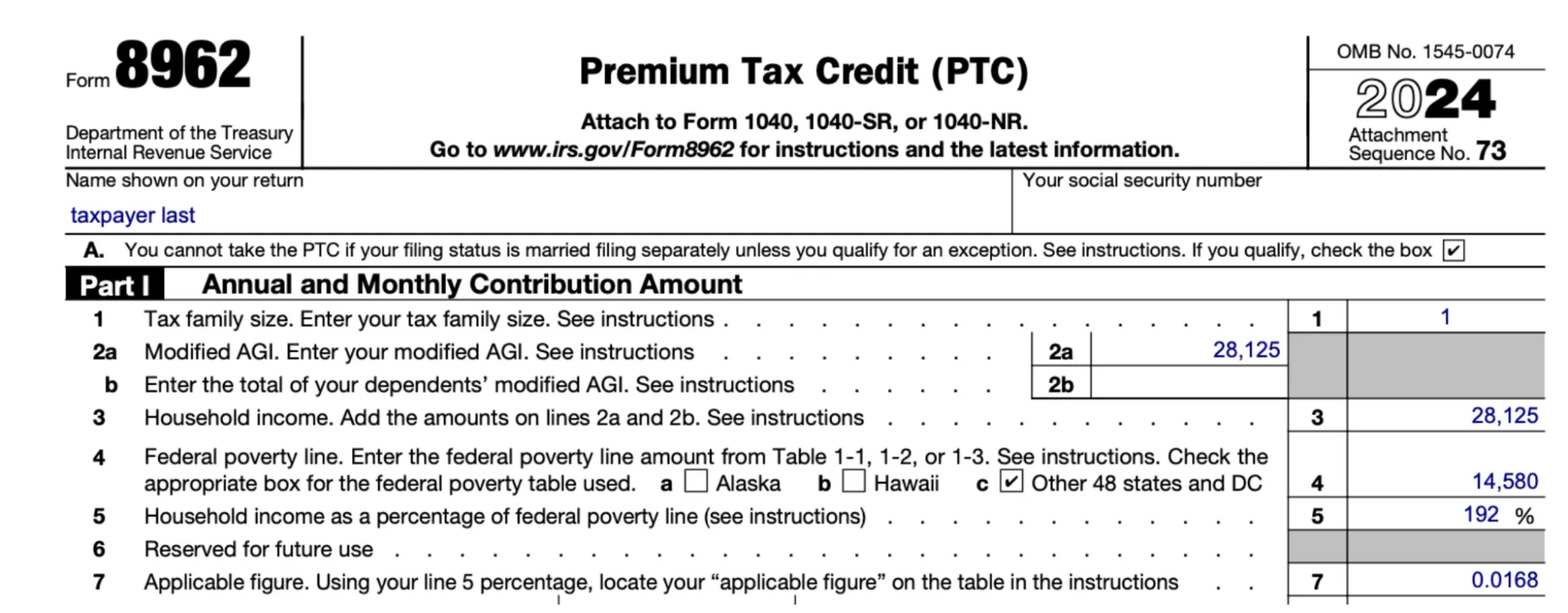
The model also uses the wrong Federal Poverty Level (FPL): $15,060 vs $14,580 (which caused additional mistakes down the form).
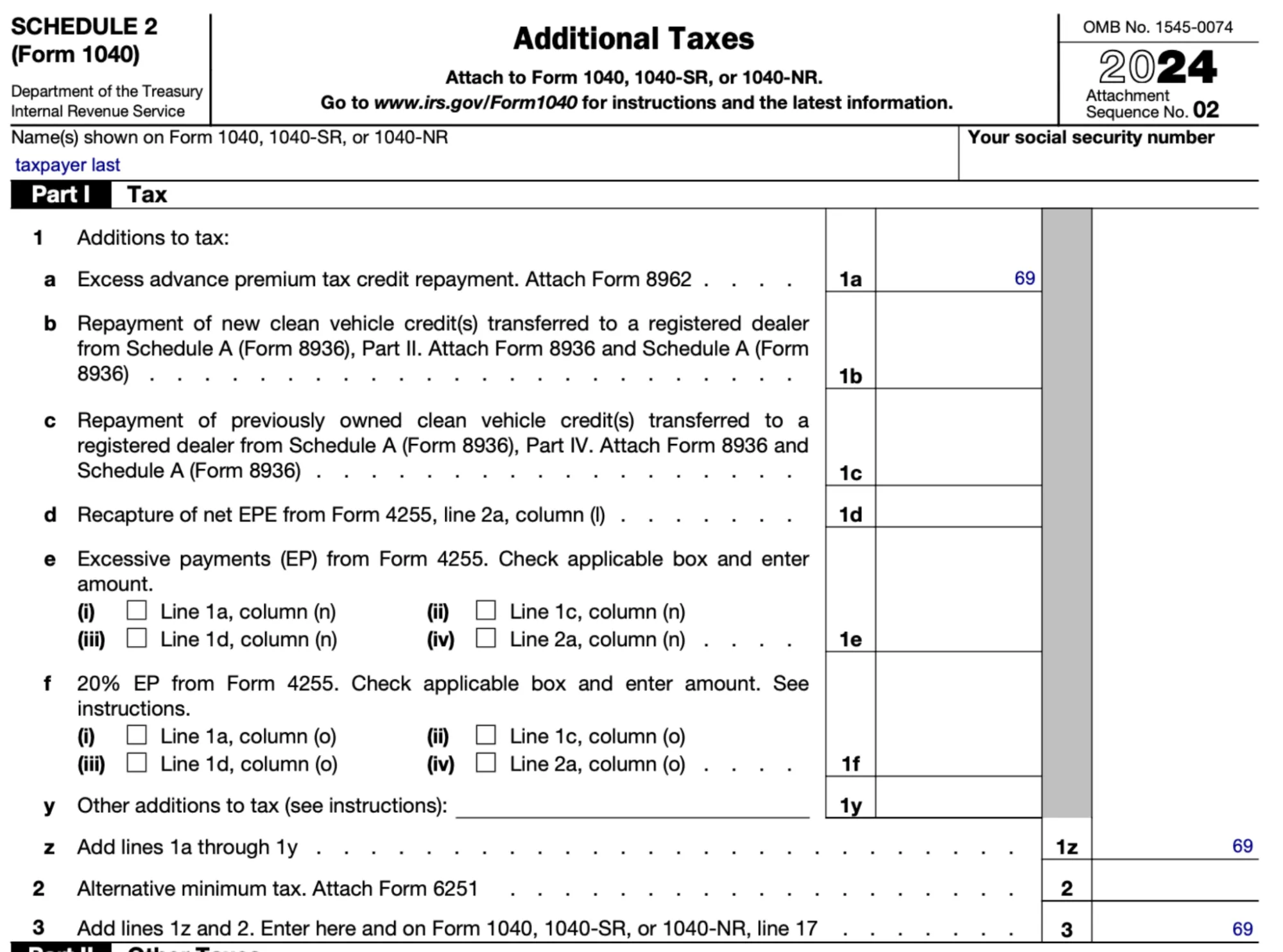
Mistakes of this nature continue through the run. For example, the model computed Schedule 2 as:
Form Schedule 2: Additional Taxes
=================================
Line 1: Tax from Form 1040, line 16 | Reference to Form 1040, line 16 | 1,391
Line 2: Excess advance premium tax credit repayment | From Form 8962, line 27 | 158
Line 3: Add lines 1 and 2 | Sum of lines 1 and 2 ($1,391 + $158) | 1,549
Line 21: Add lines 11 through 20. These are your total additional taxes | No other additional taxes apply | 0Which doesn’t match the official Schedule 2 at all:
These results point to the need for additional scaffolding, infrastructure, and augmentation that could potentially help the models compute some of the additional forms. For example, in the prompt for this experiment, the model is bootstrapped with the correct Form 1040 lines & short instructions as part of its context. We imagine similar techniques could help with additional forms, but getting this right will be tricky!
Per-provider takeaways
We only tested models that have a 2025 knowledge cutoff because those are models which have complete information about the 2024 tax year. If you're a model provider looking to test your model on this benchmark, feel free to contact us for help.
Gemini
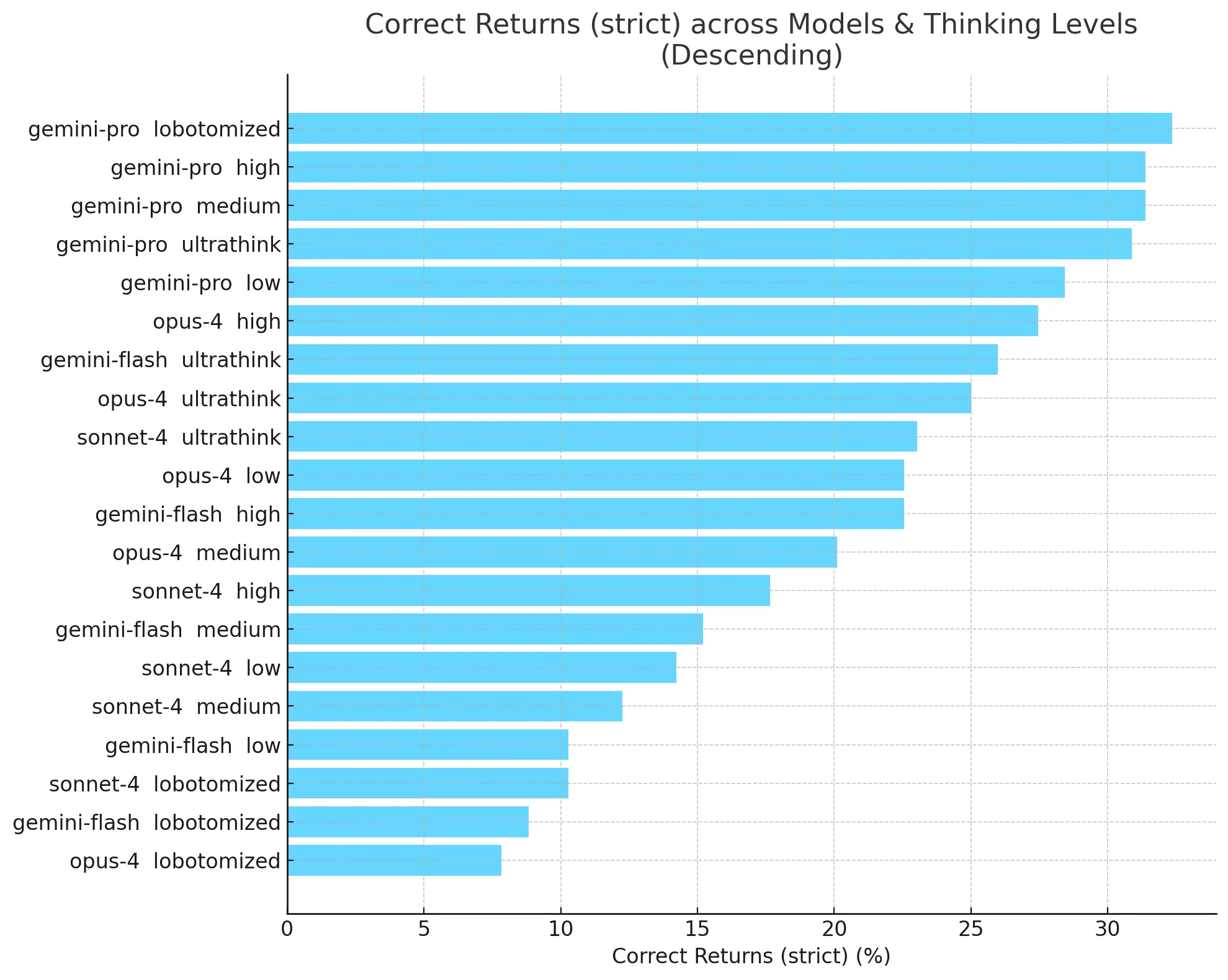
Gemini 2.5 Pro is the best-performing model on this benchmark.
- Interestingly, model performance does not increase for Gemini 2.5 Pro above a certain thinking budget. This indicates that above that thinking budget, the model is not spending its thinking tokens on anything that can improve its performance.
- By default, Gemini's API includes a dynamic thinking budget for its 2.5 Pro and 2.5 Flash models. This works well for the tax calculation task, which for the 2.5 Flash model, requires at least some thinking budget to get improved performance.

Claude
Claude Opus 4 is the second best-performing model in this benchmark, but still lags in performance behind Gemini 2.5 Pro at lower thinking budget levels.
- Claude's Opus and Sonnet models see greatly improved performance with increased thinking budgets.
- By default, Claude's API has thinking budgets disabled, which significantly hampers Claude's performance on this benchmark.
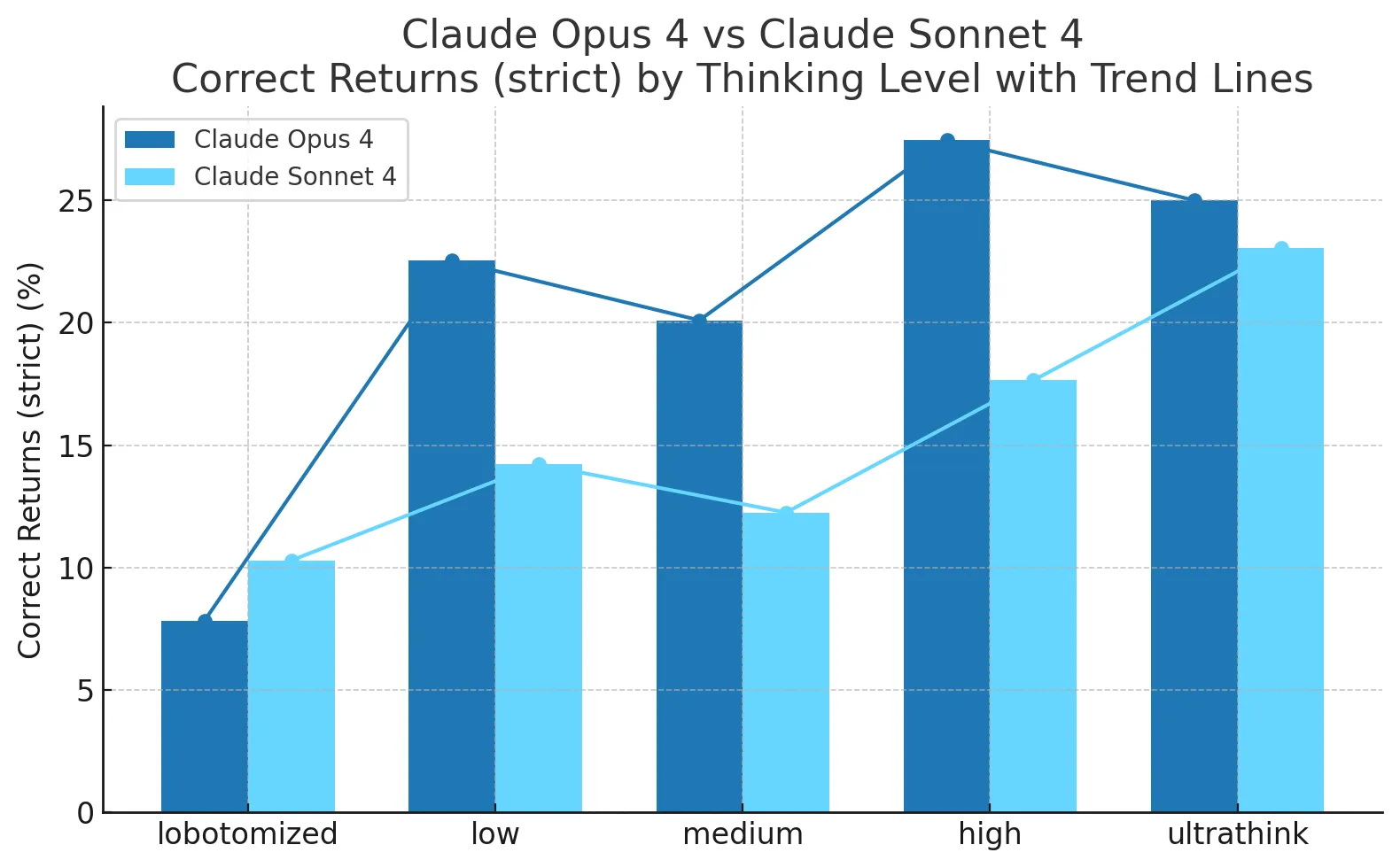
Detailed results
Here are all of the models tested, at all thinking levels:
Models are not consistent in their calculations today, as seen via the pass^k metric decreasing as k increases:
The goal posts will move
The TY24 edition of TaxCalcBench is a slimmed-down version of the true complexity of the task:
- The dataset is federal-only (42 states + D.C. levy state/local income tax)
- It covers only a relatively simple set of tax situations: the vast majority of tax forms are not covered by this dataset
- It does not expect the output to be formatted in MeF schema-compatible XML
We expect to release a yearly version of the benchmark and for future editions to add state returns, more-complex situations, and to switch to testing against proper XML output.
Applying AI to 100% correctness domains like Tax
While TaxCalcBench demonstrates the potential for AI to tackle complex tasks like personal income tax calculation, our findings make clear that current models alone aren’t yet reliable enough for real-world deployment. At Column Tax, we've learned firsthand that accurate tax computation demands deterministic precision, compliance with IRS rules, and rigorous auditability—qualities today’s frontier AI models lack. Our benchmark highlights key failure modes, such as misapplication of tax tables and eligibility criteria, pointing to critical areas for improvement.
We envision future tax-computing AI models augmented by robust infrastructure and orchestration. Our team is actively exploring new methods to scaffold models with structured tax knowledge, enforce rule compliance, and ensure accurate, consistent outputs. By iteratively expanding TaxCalcBench with more complex tax scenarios, state returns, and official XML formatting requirements, we aim to continually push the envelope, guiding the AI community toward solutions that blend model creativity with the reliability and precision necessary for real-world tax calculation.
This benchmark dataset would not have been possible without the hard work of the Tax Analyst team at Column Tax who has worked tirelessly over the past 4 years to create one of the first at-scale tax calculation engines in the past two decades and whose testing work is the underpinning and source of the data in this benchmark.
You can find the code and data for TaxCalcBench here.
____________________________
1 https://arxiv.org/abs/2009.06103
2 At the moment, the XML schemas are much too large to fit in context, and breaking them up to only include the relevant schemas would require an understanding of the tax calculations themselves and be quite a lot of scaffolding/infrastructure to provide the models.
3 There is occasionally some ambiguity with regard to rounding rules that could lead to multiple acceptable strict values.
Ready to get started?
.png)